Recurrent Neural Network¶
Let us now move on to Recurrent Neural Network (RNN). Recurrent neural network is good in handling sequential data because they have a memory component which enables this network to remember past (few) information making it better for a model requiring varying length inputs and outputs.
For example, consider the two sentences “I went to Nepal in 2009” and “In 2009,I went to Nepal.” If we ask a machine learning model to read each sentence and extract the year in which the narrator went to Nepal, we would like it to recognize the year 2009 as the relevant piece of information, whether it appears in the sixth word or the second word of the sentence. Suppose that we trained a feedforward network that processes sentences of fixed length. A traditional fully connected feedforward network would have separate parameters for each input feature, so itwould need to learn all of the rules of the language separately at each position in the sentence.
In this post, we'll implement a simple RNN, applying it to the problem of part-of-speech (POS) tagging problem.
using PyPlot
Understanding the Data¶
The data used in solving the POS tagging problem was taken from Graham Neubig's NLP Programming Tutorial. Training dataset is a collection of sentences where each word already has a POS tag attached to it :
$$word1\_tag1\;word2\_tag2\;\;...\;\; .\_.$$The function readWordTagData, reads such a file and outputs an array of :
- unique words
- unique tags
- whole dataset split into tuples containing word and its associated tag
Arrays of unique words and tags will help in one-hot vector representation which we'll feed to our neural network. In order to handle unknown words and unknown tags, I have also added $UNK\_W$ and $UNK\_T$ to these arrays.
# https://github.com/JuliaLang/julia/issues/14099
const spaces = filter(isspace, Char(0):Char(0x10FFFF));
function readWordTagData(filePath)
file = open(filePath);
vocabSet = Set{AbstractString}();
tagSet = Set{AbstractString}();
# read line
for ln in eachline(file)
word_tag = split(ln, spaces);
# remove ""
word_tag = word_tag[word_tag .!= ""]
# separate word from tag
for token in word_tag
tokenSplit = split(token, "_");
push!(vocabSet, tokenSplit[1]);
push!(tagSet, tokenSplit[2]);
end
end
close(file);
# to handle unknown words
push!(vocabSet, "UNK_W");
# to handle unknown tags
push!(tagSet, "UNK_T");
#println(vocabSet)
#println(tagSet)
vocab = collect(vocabSet);
tags = collect(tagSet);
# prepare data array
data = Tuple{AbstractString , AbstractString }[];
file = open(filePath);
# read line
for ln in eachline(file)
word_tag = split(ln, spaces);
# remove ""
word_tag = word_tag[word_tag .!= ""]
# separate word from tag
for token in word_tag
tokenSplit = split(token, "_");
push!(data, (tokenSplit[1], tokenSplit[2]));
end
end
close(file);
#println(length(data))
return vocab, tags, data;
end
Setting up RNN¶
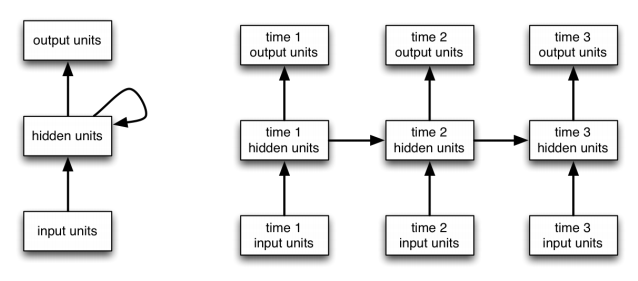
Looking at a time step $t$, an RNN receives an input $x_t$ along with the hidden state($h_{t-1}$) computed in the previous time step ($t-1$). If you unroll the RNN over few time steps then it becomes easier to understand and train the network, similar to a feedforward neural network. Any network with connections making a cycle can be unrolled into a series of feedforward network representing each time step. All these time steps share the respective weights and biases over the network and our task would be to learn these parameters using the backpropagation algorithm. It'll become clear once we get to the code.
# read data
vocabListTrain, tagListTrain, dataTrain = readWordTagData("data/pos/wiki-en-train.norm_pos");
# define the network
inputLayerSize = length(vocabListTrain);
hiddenLayerSize = 100;
outputLayerSize = length(tagListTrain);
learningRate = 1e-3;
decayRate = 0.9;
epsVal = 1e-5;
# initialize weights and biases
Wxh = randn(inputLayerSize, hiddenLayerSize)*0.01; # input to hidden
Whh = randn(hiddenLayerSize, hiddenLayerSize)*0.01; # hidden to hidden
Bh = zeros(1, hiddenLayerSize); # hidden bias
Why = randn(hiddenLayerSize, outputLayerSize)*0.01; # hidden to output
By = zeros(1, outputLayerSize); # output bias
Backpropagation Through Time (BPTT)¶
In order to learn the weights for our recurrent network, we have to generalize our backpropagation algorithm and apply it to our recurrent neural networks. This variant we are going to use is known as backpropagation through time (BPTT) since it works on sequences in time.
In the forward process, we'll take one-hot vector representation of a word and will try to predict the normalized tag probability. For that we are using the tanh activation function at the hidden layer and the softmax at the output layer. Since our network is an RNN, at time step $1$ for the first sequence, the hidden state can be a zero matrix and in the next time step we can use whatever we have calculated in the previous time step i.e., the value of the last hidden state of the first sequence can be used at time step $1$ for the next sequence and so on.
$$a_t = W_{xh}*x_{t} + W_{hh}*h_{t-1} + B_h$$$$h_t = tanh(a_t)$$$$z_t = W_{hy}*h_t + B_y$$$$\hat y_t = softmax(z_t)$$We'll save the hidden state values and the normalized probabilities at the each time step to use during the backward process.
For each time step we define out cross entropy cost function as:
$$J_t(W_xh, W_hh, W_hy) = J_t(W) = - y_t* \log (\hat y_t)$$Since our input is a sequence we define the cost for the whole sequence as:
$$J(W) = \sum_{t}J_t(W) = - \sum_{t} y_t* \log (\hat y_t)$$function forwardRNN(x::Array{Vector{Float64},1}, y::Array{Vector{Float64},1},
h::Array{Array{Float64,2},1}, p::Array{Vector{Float64},1}, hPrev::Array{Float64,2})
global Wxh, Whh, Why, Bh, By;
cost = 0;
# for each time t in x
# unrolling RNN -> Feedforward NN step
for time in 1:length(x)
if time == 1
h[time] = tanh(x[time]'*Wxh + hPrev*Whh .+ Bh);
else
h[time] = tanh(x[time]'*Wxh + h[time-1]*Whh .+ Bh);
end
# output layer
score = h[time]*Why .+ By;
p_softmax = exp(score) / sum(exp(score));
p[time] = vec(p_softmax); # output probability distribution (at time t)
cost += -sum(log(y[time]'*p[time])) # assuming y is a one-hot vector
end
return cost;
end
In the backward process, we apply the chain rule as usual to backpropagate the errors and calculate the gradients. We already defined our cost function as :
$$J(W) = - \sum_{t} y_t* \log (\hat y_t)$$Since all output units contribute to the error of each hidden unit we sum up all the gradients calculated at each time step in the sequence and use it to update the parameters. So our parameter gradients becomes :
$$\frac{\partial J_t}{\partial W_{hy}} = \sum_t \frac{\partial J}{\partial z_t}*\underbrace{\frac{\partial z_t}{\partial W_{hy}}}_{h_t}$$$$\frac{\partial J_t}{\partial W_{hh}} = \sum_t \frac{\partial J}{\partial h_t}*\underbrace{\frac{\partial h_t}{\partial W_{hh}}}_{(1-h_t^2)*h_{t-1}}$$$$\frac{\partial J_t}{\partial W_{xh}} = \sum_t \frac{\partial J}{\partial h_t}*\underbrace{\frac{\partial h_t}{\partial W_{xh}}}_{(1-h_t^2)*x_{t}}$$where,
$$\frac{\partial J}{\partial z_t} = \underbrace{\frac{\partial J}{\partial J_t}}_{= 1} * \frac{\partial J_t}{\partial z_t}$$From the previous post we know that:
$$\frac{\partial J_t}{\partial z_t} = \hat y_t - y_t $$Point to note here is that change in $z_t$ does not affect the cost at other time steps. But that is not the case with $h_t$. A change in $h$ at time step $t$ is going to change the cost at $t+1$, $t+2$ ...$T$. In other words, $h_t$ is going to affect $\hat y_t$ and $h_{t+1}$, which in turn will propagate forward and affect $h$ at other time steps.
So let us look at the end of the sequence, i.e., at time step $T$: $$\begin{aligned} \frac{\partial J}{\partial h_T} &= \frac{\partial J}{\partial z_T}*\frac{\partial z_T}{\partial h_T} \\ &= (\hat y_T - y_T)*W_{hy} \end{aligned} $$
and at other time step $t$ in the sequence,
$$\begin{aligned} \underbrace{\frac{\partial J}{\partial h_t}}_{dh} &= \underbrace{\left (\frac{\partial J}{\partial z_t}*\frac{\partial z_t}{\partial h_t} \right )}_{a} + \underbrace{\left (\frac{\partial J}{\partial h_{t+1}}*\frac{\partial h_{t+1}}{\partial h_t}\right )}_{dhnext}\end{aligned} $$We can work out $a$ from the other equations above. In $dhnext$, the value of $\frac{\partial J}{\partial h_{t+1}}$ will backpropagate since we would have already calculated this at time step $(t+1)$ before coming on to the time step $t$. For the rest : $$\frac{\partial h_{t+1}}{\partial h_t} = W_{hh}*(1-h_t^2)$$
A similar but a different way of working out the equations can be seen in Richard Sochers's Recurrent Neural Network lecture slide.

In the code we are also using gradient clipping to handle the gradient explosion problem. I first observed this being used in Andrej Karpathy's min-char-rnn.py, and then in this paper.
We propose a gradient norm clipping strategy to deal with exploding gradients and a soft constraint for the vanishing gradients problem.
function backwardRNN(x::Array{Vector{Float64},1}, y::Array{Vector{Float64},1},
h::Array{Array{Float64,2},1}, p::Array{Vector{Float64},1}, hPrev::Array{Float64,2})
global Wxh, Whh, Why, Bh, By;
dWxh = zeros(size(Wxh));
dWhh = zeros(size(Whh));
dBh = zeros(size(Bh));
dWhy = zeros(size(Why));
dBy = zeros(size(By));
dh = zeros(size(Bh)); # error from the following time step
dhnext = zeros(size(h[1]));
for time in length(x):-1:1
# output layer error
dy = p[time] - y[time]; #assuming y is a one hot vector
# output gradient
dWhy = dWhy + (dy * h[time])';
dBy = dBy + dy';
# backpropagate
dh = (Why*dy)' + dhnext;
dhRaw = (1 - (h[time].*h[time])) .* dh;
# hidden layer gradient
dWxh = dWxh + (x[time] * dhRaw);
dBh = dBh + dhRaw;
if time == 1
dWhh = dWhh + (hPrev' * dhRaw);
else
dWhh = dWhh + (h[time-1]' * dhRaw);
end
dhnext = dhRaw*Whh;
end
# clip to mitigate exploding gradients
dWxh = clamp(dWxh, -5, 5);
dWhh = clamp(dWhh, -5, 5);
dBh = clamp(dBh, -5, 5);
dWhy = clamp(dWhy, -5, 5);
dBy = clamp(dBy, -5, 5);
return dWxh, dWhh, dBh, dWhy, dBy;
end
Gradient Check¶
The implementation of backpropagation algorithm hasn't changed much over these series of posts but it's always good to keep a tool in hand to check whether our code is correct or not. We first go through the backpropagation step to calculate the analytical gradients. Then we perturb an element in the weight matrix and go through the forward step to calculate the cost calculating the numerical gradient as :
$$\begin{align} \frac{d}{d\theta}J(\theta) = \lim_{\epsilon \rightarrow 0} \frac{J(\theta+ \epsilon) - J(\theta-\epsilon)}{2 \epsilon}. \end{align}$$By comparing the relative error between the analytical gradient and the numerical gradient we can be sure that there is no bug in calculating the gradients. It should be very very small, less than $1e^{-5}$.
Use relative error for the comparison. What are the details of comparing the numerical gradient $f′n$ and analytic gradient $f′a$? That is, how do we know if the two are not compatible? You might be tempted to keep track of the difference $∣fa′−fn′∣$ or its square and define the gradient check as failed if that difference is above a threshold. However, this is problematic. For example, consider the case where their difference is 1e-4. This seems like a very appropriate difference if the two gradients are about 1.0, so we'd consider the two gradients to match. But if the gradients were both on order of 1e-5 or lower, then we'd consider 1e-4 to be a huge difference and likely a failure. Hence, it is always more appropriate to consider the relative error :
$$\frac{\mid f'_a - f'_n \mid}{\max(\mid f'_a \mid, \mid f'_n \mid)}$$which considers their ratio of the differences to the ratio of the absolute values of both gradients. Notice that normally the relative error formula only includes one of the two terms (either one), but I prefer to max (or add) both to make it symmetric and to prevent dividing by zero in the case where one of the two is zero (which can often happen, especially with ReLUs). However, one must explicitly keep track of the case where both are zero and pass the gradient check in that edge case. In practice :
- relative error > 1e-2 usually means the gradient is probably wrong
- 1e-2 > relative error > 1e-4 should make you feel uncomfortable
- 1e-4 > relative error is usually okay for objectives with kinks. But if there are no kinks (e.g. use of tanh nonlinearities and softmax), then 1e-4 is too high.
- 1e-7 and less you should be happy.
Also keep in mind that the deeper the network, the higher the relative errors will be. So if you are gradient checking the input data for a 10-layer network, a relative error of 1e-2 might be okay because the errors build up on the way. Conversely, an error of 1e-2 for a single differentiable function likely indicates incorrect gradient.
Its been also suggested to:
- not perform the gradient check at the first iteration
- turn off regularization
- check some of the dimensions of the gradient and assume that the others are correct
# gradient checking
function gradCheck(inputs::Array{Vector{Float64},1}, targets::Array{Vector{Float64},1},
h::Array{Array{Float64,2},1}, p::Array{Vector{Float64},1}, hPrev::Array{Float64,2})
paramNameList = ["Wxh", "Whh", "Bh", "Why", "By"];
# collect paramters
global Wxh, Whh, Why, Bh, By;
paramList = [x for x=(Wxh, Whh, Bh, Why, By)];
num_checks = 2;
delta = 1e-5;
# collect parameter gradients
cost = forwardRNN(inputs, targets, h, p, hPrev);
dWxh, dWhh, dBh, dWhy, dBy = backwardRNN(inputs, targets, h, p, hPrev);
dParamList = [x for x=(dWxh, dWhh, dBh, dWhy, dBy)];
for (param,dparam,name) in zip(paramList, dParamList, paramNameList)
# validate the size of the parameter and its gradient
s0 = size(dparam);
s1 = size(param);
if s0 != s1
println("Error dims dont match: ", s0," and ",s1);
end
println(name)
for i in 1:num_checks
ri = rand(1:length(param));
# evaluate cost at [x + delta] and [x - delta]
old_val = param[ri];
param[ri] = old_val + delta;
cg0 = forwardRNN(inputs, targets, h, p, hPrev);
param[ri] = old_val - delta;
cg1 = forwardRNN(inputs, targets, h, p, hPrev);
param[ri] = old_val # reset old value for this parameter
# fetch both numerical and analytic gradient
grad_analytic = dparam[ri];
grad_numerical = (cg0 - cg1) / ( 2 * delta );
rel_error = abs(grad_analytic - grad_numerical) / abs(grad_numerical + grad_analytic);
println(grad_numerical,", ", grad_analytic, " => ",rel_error);
# rel_error should be on order of 1e-7 or less
if rel_error > 1e-5
error("Gradient check failed.");
end
end
println("Gradient check passed.")
end
end
I ran the gradient check for a sample dataset and used the sequence length of 1. This operation is commented out in the code below because it is very computation expensive. The train method loops over each sequence, and updates the weights/biases matrices using the backpropagation algorithm to calculate the gradients for that sequence.
function train(data::Array{Tuple{AbstractString,AbstractString},1}, vocabList::Array{AbstractString,1}
, tagList::Array{AbstractString,1}, numItr::Int64, seqLength::Int64, sampleCostAtItr::Int64)
global Wxh, Whh, Why, Bh, By;
numIterations = numItr * length(data);
costList = []; # store cost per sampled iteration
ptr = 1;
p = [zeros(length(tagList)) for i in 1:seqLength];
h = Array{Float64,2}[zeros(1,hiddenLayerSize) for i in 1:seqLength]; # hidden layers (at time t)
hPrev = zeros(1, hiddenLayerSize);
for itr in 1:numIterations
# take care of the sequence length
if ptr+seqLength-1 > length(data) # whenever we are looking at the data from the start
# reset RNN memory
hPrev = zeros(1, hiddenLayerSize);
# go from start of data
ptr = 1
end
# generate sequence
seqData = data[ptr:ptr+seqLength-1];
x = Vector{Float64}[];
y = Vector{Float64}[];
for word_tag in seqData
word = word_tag[1];
tag = word_tag[2];
# convert to one-hot vectors
# words
wordVec = zeros(length(vocabList));
findWord = collect(vocabList.==word)
if length(findWord[findWord.==true]) == 0
# unknown word: UNK_W
findWord[length(findWord)] = true;
end
wordVec[findWord] = 1;
# tags
tagVec = zeros(length(tagList));
findTag = collect(tagList.==tag)
if length(findTag[findTag.==true]) == 0
# unknown tag: UNK_T
findTag[length(findTag)] = true;
end
tagVec[findTag] = 1;
# push to the sequence
push!(x , wordVec);
push!(y , tagVec);
end
# gradient check
#gradCheck(x, y, h, p, hPrev);
# feedforward
cost = forwardRNN(x, y, h, p, hPrev);
# sample cost
if itr%sampleCostAtItr == 1
push!(costList, cost);
end
# backpropagate
dWxh, dWhh, dBh, dWhy, dBy = backwardRNN(x, y, h, p, hPrev);
# update weights
Wxh += -learningRate * dWxh;
Whh += -learningRate * dWhh;
Bh += -learningRate * dBh;
Why += -learningRate * dWhy;
By += -learningRate * dBy;
# previous output as hidden input for the next sequence
hPrev = h[length(h)];
# move data pointer
ptr += seqLength;
end
return costList;
end
We'll run the training step for the whole data 20 times, using an input sequence of size 2. Since there will be lot of iteration we'll sample the cost at every 1000 interation.
# MAIN
# number of steps to unroll the RNN for
seqLen = 2
# run through the data n times
numIterOverData = 20;
# sample cost after each n iteration
sampleCostAtEveryItr = 1000;
J = train(dataTrain, vocabListTrain, tagListTrain, numIterOverData, seqLen, sampleCostAtEveryItr);
# plot the cost per iteration
sampleIdxJ = [1+sampleCostAtEveryItr*i for i in 0:length(J)-1]
plot(sampleIdxJ, J)
xlabel("Sampled Iterations")
ylabel("Cost")
grid("on")

The cost in the graph seems to be decreasing with respect to the iteration. The cost is not smoothly decreasing because we are kind of running a mini-batch gradient descent hence it is just an estimate of the cost over the whole dataset. It's in my TODO list to investigate it more thoroughly some day since the graph looks a bit ugly. For now, let's check how it is performing. To find the accuracy, we'll use the learned model and go through the forward step to make the prediction.
function findAccuracy(data::Array{Tuple{AbstractString,AbstractString},1}, vocabList::Array{AbstractString,1}
, tagList::Array{AbstractString,1}, seqLength::Int64)
correct = 0;
ptr=1;
p = [zeros(length(tagList)) for i in 1:seqLength];
h = Array{Float64,2}[zeros(1,hiddenLayerSize) for i in 1: seqLength]; # hidden layers (at time t)
hPrev = zeros(1,hiddenLayerSize);
for i in 1:length(data)/seqLength
# prepare inputs (we're sweeping from left to right in steps seq_length long)
if ptr+seqLength-1 > length(data) # whenever we are looking at the data from the start
break # return if data is alread read
end
# generate sequence
seqData = data[ptr:ptr+seqLength-1];
x = Vector{Float64}[];
y = Vector{Float64}[];
for word_tag in seqData
word = word_tag[1];
tag = word_tag[2];
# convert to one-hot vectors
# words
wordVec = zeros(length(vocabList));
findWord = collect(vocabList.==word)
if length(findWord[findWord.==true]) == 0
# unknown word: UNK_W
findWord[length(findWord)] = true;
end
wordVec[findWord] = 1;
# tags
tagVec = zeros(length(tagList));
findTag = collect(tagList.==tag)
if length(findTag[findTag.==true]) == 0
# unknown tag: UNK_T
findTag[length(findTag)] = true;
end
tagVec[findTag] = 1;
# push to the sequence
push!(x , wordVec);
push!(y , tagVec);
end
# feedforward
cost = forwardRNN(x, y, h, p, hPrev);
hPrev = h[size(h,1)];
prediction = [indmax(p[j]) for j in 1:length(seqData)];
truth = [indmax(y[j]) for j in 1:length(seqData)];
# accuracy
for j in 1:length(seqData)
if truth[j] == prediction[j]
correct = correct + 1;
end
end
ptr += seqLength; # move data pointer
end
accuracy = correct/length(data)*100;
return accuracy;
end
accuracy = findAccuracy(dataTrain, vocabListTrain, tagListTrain, seqLen);
println("accuracy: ", accuracy);
Test data¶
The test data consists of two files, one with regular sentences in English and other with their corresponding tags. I am just mapping the words and tags to produce an array of tuples similar to what we used in the training step.
function readData(filePath)
file = open(filePath);
# read line
wordList = [];
for ln in eachline(file)
words = split(ln, spaces);
# remove ""
words = words[words .!= ""]
# append to the list
wordList = [words; wordList];
end
close(file);
return wordList;
end
# read test data
wordListTest = readData("data/pos/wiki-en-test.norm");
tagListTest = readData("data/pos/wiki-en-test.pos");
dataTest = Tuple{AbstractString , AbstractString }[];
for i in 1:length(wordListTest)
push!(dataTest, (wordListTest[i], tagListTest[i]));
end
# will use vocab list and tag list created at the training time
accuracy = findAccuracy(dataTest, vocabListTrain, tagListTrain, seqLen);
println("accuracy: ", accuracy);
As you can see, RNN performed quite well on both the train and the test data set. But RNN has it own problems. It suffers from vanishing/exploding gradient problem.
As introduced in Bengio et al. (1994), the exploding gradients problem refers to the large increase in the norm of the gradient during training. Such events are caused by the explosion of the long term components, which can grow exponentially more then short term ones. The vanishing gradients problem refers to the opposite behaviour, when long term components go exponentially fast to norm 0, making it impossible for the model to learn correlation between temporally distant events.
In order to tackle these problems, people have come up with few other variants of RNN such as LSTM (Long-Short Term Memory) and GRU (Gated Recurrent Unit). Maybe I'll cover some of them in the coming posts. Till then, keep it constructive and enjoy!
References:
- The Unreasonable Effectiveness of Recurrent Neural Networks
- Recurrent Neural Networks - cs224d
- Sequence Modeling: Recurrent and Recursive Nets
- A Critical Review of Recurrent Neural Networks for Sequence Learning
- Backpropagation Through Time: What it does and how to do it
- A guide to recurrent neural networks and backpropagation
- Lec [5.1]: Deep Learning, Recurrent neural network
- Training RNNs
- On the difficulty of training Recurrent Neural Networks
- Deep Learning Lecture 12: Recurrent Neural Nets and LSTMs
- NLP Programming Tutorial
- Statistical Language Models based on Neural Networks
- A Simple Way to Initialize Recurrent Networks of Rectified Linear Units