This post is a continuation of the Neural Network post where we learned about the basics of a neural network and applied it on the handwritten digit recognition problem. Here we'll cover the following topics which can help our neural network to perform better in terms of the accuracy of the model.
So let's get started!
using MNIST
using PyPlot
ReLU Activation Function : $$f(x) = max(0, x)$$
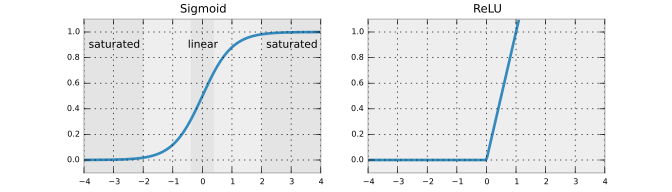
We have already seen the sigmoid function instead of which we'll use ReLU activation function for the input and hidden layers in the current neural network architecture because it is faster and does not suffer from the vanishing gradient problem.
- Biological plausibility: One-sided, compared to the antisymmetry of tanh.
- Sparse activation: For example, in a randomly initialized network, only about 50% of hidden units are activated (having a non-zero output).
- Efficient gradient propagation: No vanishing gradient problem or exploding effect.
- Efficient computation: Only comparison, addition and multiplication.
For the first time in 2011, the use of the rectifier as a non-linearity has been shown to enable training deep supervised neural networks without requiring unsupervised pre-training. Rectified linear units, compared to sigmoid function or similar activation functions, allow for faster and effective training of deep neural architectures on large and complex datasets.
Potential problems: Non-differentiable at zero: however it is differentiable at any point arbitrarily close to 0.
"What neuron type should I use?" Use the ReLU non-linearity, be careful with your learning rates and possibly monitor the fraction of "dead" units in a network. If this concerns you, give Leaky ReLU or Maxout a try. Never use sigmoid. Try tanh, but expect it to work worse than ReLU/Maxout.
# ReLU function
function relu(z::Matrix{Float64})
return max(0.0, z);
end
# sigmoid function
function sigmoid(z::Matrix{Float64})
g = 1.0 ./ (1.0 + exp(-z));
return g;
end
Softmax Function : $$f_i(x) = \frac{e^{x_i}}{\sum_k e^{x_k}}$$
Softmax function gives us normalized class probabilities. It takes the input, exponentiates it to generate unnormalized probabilities and then it uses a normalization factor to result in normalized probabilities. The output for each class lies between $0$ and $1$, and the sum of all the class probabilities is equal to $1$.
Forward Process
I have re-structured the program to have replaceable components to make the experiment easy. There is a small change in the architecture of the neural network:
- output layer will always be using the Softmax activation function
- rest of all the layers we'll either use ReLU activation function
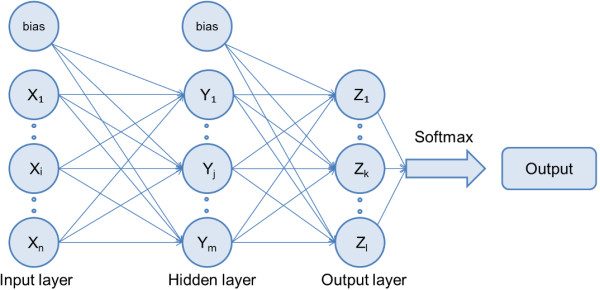
With the introduction of the ReLU and Softmax function we can look at our forward step. At the first input layer: $$a^{(1)} = x$$
At the hidden layer: $$ \begin{array}{ll} z^{(2)} = \theta^{(1)}*a^{(1)} + bias^{(1)} \\[2ex] a^{(2)} = ReLU(z^{(2)}) \end{array} $$
At the output layer: $$ \begin{array}{ll} z^{(3)} = \theta^{(2)}*a^{(2)} + bias^{(2)} \\[2ex] \hat y = softmax(z^{(3)}) \end{array} $$
Each entry in $p$ vector defines our output normalized probability for that specific class.
function forwardNN(activationFn::Function, x::Matrix{Float64})
global network;
# collect input for each layer
# the last element will be the output from the neural network
activation = Matrix{Float64}[];
# initialize activation vector with the actual data
push!(activation, x);
for layer in 1:length(network)-1
push!(activation, activationFn((activation[layer]*network[layer][1]) .+ network[layer][2]))
end
# softmax on last layer
score = activation[length(network)]*network[length(network)][1] .+ network[length(network)][2]
exp_scores = exp(score);
yCap = exp_scores ./ sum(exp_scores, 2);
return activation, yCap;
end
Cost Function: $J$
The last time we converted each output to an array of size $10$ with $1$ on the index representing the actual output and $0$ on the rest of the indices. Therefore we used a special case of the cross-entropy cost function where number of classes is equal to 2, assuming all of the output classes are independent of each other:
$$J(\theta) = -\frac{1}{m}\sum_{i=1}^{m} \sum_{i=1}^{k}[ y^{(i)}_k\log{(h_{\theta}(x^{(i)})_k)} + (1-y^{(i)}_k)\log({1-(h_{\theta}(x^{(i)}))_k)}]$$If we have multiple independent binary attributes by which to classify the data, we can use a network with multiple logistic outputs and cross-entropy error. For multinomial classification problems (1-of-n, where n > 2) we use a network with n outputs, one corresponding to each class, and target values of 1 for the correct class, and 0 otherwise. Since these targets are not independent of each other, however, it is no longer appropriate to use logistic output units. The corect generalization of the logistic sigmoid to the multinomial case is the softmax activation function.
Since we are using softmax in the output layer, the probability for one class is divided by the sum of probabilities for all the classes. As a result, we will be using the generalized cross entropy cost function:
\begin{align} J(\theta) = - \left[ \sum_{i=1}^{m} \sum_{k=1}^{K} 1\left\{y^{(i)} = k\right\} \log \frac{\exp(\theta^{(k)\top} x^{(i)})}{\sum_{j=1}^K \exp(\theta^{(j)\top} x^{(i)})}\right] \end{align}In the probabilistic interpretation, we are therefore minimizing the negative log likelihood of the correct class, which can be interpreted as performing Maximum Likelihood Estimation (MLE).
More detailed information can be found here.
function costFunction(truth::Vector{Float64}, probability::Matrix{Float64})
global network;
# average cross-entropy loss
m = size(truth,1)
corect_logprobs = [-log(probability[j,convert(Int32, truth[j])]) for j in 1:m];
data_loss = sum(corect_logprobs)/m;
#L2 regularization
reg_loss = 0;
for j in 1:length(network)
reg_loss = reg_loss + 0.5*lambda*sum(network[j][1].^2)/m;
end
loss = data_loss + reg_loss;
return loss;
end
# gradient of the sigmoid function evaluated at a
function sigmoidGradient(a::Matrix{Float64})
return a.*(1-a);
end
# gradient of the ReLU function evaluated at a
function reluGradient(a::Matrix{Float64})
grad = ones(a);
grad[a.<=0] = 0;
return grad;
end
Backward process
The algorithm to learn the parameters is still the same, backpropagation. We need to calculate the parameter gradients to update them using the chain rule. For simplicity consider the cost function for a single input,
\begin{align} J(\theta) &= - \left[ \sum_{k=1}^{K} y_k* \log (\hat y_k) \right] \end{align}where,
$$\hat y_k = softmax(z^3_k) = \frac{\exp(z^3_k)}{\sum_{j=1}^K \exp(z^3_j) }$$and $y_k$ is either $0$ or $1$ as per the probability of the correct class.
therefore, $$ \frac{\partial J}{\partial \hat y_k} = − \frac{y_k}{\hat y_k} $$ $$ \frac{\partial \hat y_k}{\partial z^{(3)}_i} = \begin{cases} \hat y_k(1-\hat y_k), & \text{i = k} \\[2ex] -\hat y_i \hat y_k, & \text{i $\neq$ k} \\ \end{cases} \\ $$
$$\begin{eqnarray} \frac{\partial J}{\partial z^{(3)}_i} &=&\sum_{k = 1}^{K}\frac{\partial J}{\partial \hat y_k}\frac{\partial \hat y_k}{\partial z^{(3)}_i} \\ \nonumber &=& \underbrace{\frac{\partial J}{\partial \hat y_i}\frac{\partial \hat y_i}{\partial x_i}}_{i = k} + \underbrace{\sum_{k \neq i}\frac{\partial J(\theta)}{\partial \hat y_k}\frac{\partial \hat y_k}{\partial x_i}}_{i \neq k} \\ \nonumber &=&-y_i(1 - \hat y_i) + \sum_{k \neq i} y_k \hat y_k \\ \nonumber &=&-y_i + \sum_{k} y_k \hat y_k \\ \nonumber &=& \hat y_i - y_i \\ \end{eqnarray} $$The correct output element in the vector $y$ is always $1$ else $0$ since we are now dealing with the normalized class probabilities.
For the softmax output layer:
$$ \begin{eqnarray} \dfrac{\partial J}{\partial \theta^{(2)}} &=& \dfrac{\partial J}{\partial z^{(3)}} \dfrac{\partial z^{(3)}}{\partial \theta^{(2)}} \\ &=& (\hat y - y)* a^{(2)} \end{eqnarray} $$$$ \begin{eqnarray} \dfrac{\partial J}{\partial bias^{(2)}} &=& \dfrac{\partial J}{\partial z^{(3)}} \dfrac{\partial z^{(3)}}{\partial bias^{(2)}} \\ &=& (\hat y - y)* 1 \end{eqnarray} $$For the hidden layer with the ReLU activation function:
$$\begin{eqnarray} \frac{\partial J}{\partial \theta^{(1)}} &=&\frac{\partial J}{\partial z^{(3)}}\frac{\partial z^{(3)}}{\partial g(z^{(2)})}\frac{\partial g(z^{(2)})}{\partial z^{(2)}}\frac{\partial z^{(2)}}{\partial \theta^{(1)}}\\ \nonumber &=& (\hat y - y)* \theta^{(2)} * g'(z^{(2)})*a^{(1)} \\ \nonumber \end{eqnarray}$$$$\begin{eqnarray} \frac{\partial J}{\partial bias^{(1)}} &=&\frac{\partial J}{\partial z^{(3)}}\frac{\partial z^{(3)}}{\partial g(z^{(2)})}\frac{\partial g(z^{(2)})}{\partial z^{(2)}}\frac{\partial z^{(2)}}{\partial bias^{(1)}}\\ \nonumber &=& (\hat y - y)* \theta^{(2)} * g'(z^{(2)})*1 \\ \nonumber \end{eqnarray}$$Now we can update the weights as:
$$\theta^{(l)} \leftarrow \theta^{(l)} - \alpha \dfrac{\partial J}{\partial \theta^{l}}$$All the above calculations is being performed by the backwordNN and the updateThetas method below.
function backwardNN(activationFnGrad::Function, a::Vector{Matrix{Float64}}, y::Vector{Float64}, dscores::Matrix{Float64})
global network;
m = size(y,1);
delta = Array(Matrix{Float64}, 1,length(network));
# start from the last layer to backpropagate the error
# compute the gradient on scores
for j in 1:size(dscores,1)
dscores[j,convert(Int32, y[j])] -= 1;
end
delta[length(network)] = dscores/m; # normalization factor
# backpropagate
for j in length(network)-1:-1:1
delta[j] = delta[j+1]*network[j+1][1]'.*activationFnGrad(a[j+1]);
end
return delta;
end
function updateThetas(a::Vector{Matrix{Float64}}, delta::Matrix{Matrix{Float64}})
global network;
for j in 1:length(network)
# update theta
network[j][1] = network[j][1] - alpha*(a[j]'*delta[j] + lambda*network[j][1])
# update bias
network[j][2] = network[j][2] - alpha*sum(delta[j],1);
end
end
function predict(activationFn, data::Matrix{Float64})
activation, probs = forwardNN(activationFn, data);
predicted_class = [indmax(probs[i,:]) for i in 1:size(probs,1)]
return predicted_class;
end
function accuracy(truth, prediction)
correct = 0;
for i in 1:length(truth)
if truth[i] == prediction[i]
correct = correct + 1;
end
end
println("training accuracy: ", correct/length(truth)*100);
end
Training a model
Based on the new structure of the program, we'll build up our neural network and train our model.
Load Data
# ===================
# load training data
# ===================
X,Y = traindata(); #X:(784x60000), y:(60000x1)
X /= 255.0; # scale the input between 0 and 1
X = X'; #X:(60000X784)
Y = Y+1; # adding 1 to handle index, hence value 1 represent digit 0 now
# number of instances
println(size(Y,1));
Define Network
inputLayerSize = size(X,2);
hiddenLayerSize = 100;
outputLayerSize = 10;
# define a network
network = [];
# add first layer to the network
layer1 = Array(Matrix{Float64}, 1,2)
#theta1
layer1[1] = 0.01*randn(inputLayerSize, hiddenLayerSize);
#bias1
layer1[2] = zeros(1, hiddenLayerSize);
push!(network,layer1);
# add second layer to the network
layer2 = Array(Matrix{Float64}, 1,2)
#theta2
layer2[1] = 0.01*randn(hiddenLayerSize, outputLayerSize);
#bias2
layer2[2] = zeros(1, outputLayerSize);
push!(network,layer2);
Training: Mini-batch gradient descent
The last time we used gradient descent to train our model. In this implementation we'll switch to Mini-Batch gradient descent algorithm which is not much different from regular gradient descent. It's just that instead of working on the whole dataset we'll work on a smaller dataset in each iteration. Because of this change our training algorithm will become computationally faster since large datasets are difficult to handle in memory which makes vectorization much less efficient.
In particular, suppose that our error function is particularly pernicious and has a bunch of little valleys. If we used the entire training set to compute each gradient, our model would get stuck in the first valley it fell into (since it would register a gradient of 0 at this point). If we use smaller mini-batches, on the other hand, we'll get more noise in our estimate of the gradient. This noise might be enough to push us out of some of the shallow valleys in the error function.
- Quora
One thing to take care in the while training is that mini-batches need to be balanced for classes otherwise the estimation of the gradient using mini-batch gradient descent would be way off then the gradient calculated using the whole dataset.
alpha = 1e-0; # step size
lambda = 1e-3; # regularization factor
numItr = 1500;
sampleCostAtEveryItr = 10;
batchSize = convert(Int32,floor(size(X,1)/10));
J = [];
for itr in 1:numItr
# take next batch of random instances
minibatch = collect(rand(1:size(X,1), batchSize));
# feedforward
activations, probs = forwardNN(relu, X[minibatch,:]);
# cost
if itr%sampleCostAtEveryItr == 1
activationsX, probsX = forwardNN(relu, X);
push!(J, costFunction(Y, probsX));
end
# backpropagation
newThetas = backwardNN(reluGradient, activations, Y[minibatch], probs);
# update parameters
updateThetas(activations, newThetas);
end
The code above is using ReLU activation function for the hidden layers but the program is modular enough to let us experiment with different activation functions, for example sigmoid.
Prediction and Accuracy
accuracy(Y, predict(relu, X));
This is approximately 10% improvement over our previous implementation.
# plot the cost per iteration
sampleIdxJ = [1+sampleCostAtEveryItr*i for i in 0:length(J)-1]
plot(sampleIdxJ, J)
xlabel("Sampled Iterations")
ylabel("Cost")
grid("on")

The spikes in the graph are due to the use of mini-batch gradient descent, which estimates the cost over the whole dataset hence sometimes moves away from the minima but in the end converges satisfactorily.
# test data
XTest,YTest = testdata();
XTest /= 255.0;
XTest = XTest';
YTest = YTest+1;
accuracy(YTest, predict(relu, XTest));
References:
- Rectified linear unit (ReLU))
- Learning representations by back-propagating errors
- Practical recommendations for gradient-based training of deep architectures
- Efficient BackProp
- Deep Learning
- word2vec Parameter Learning Explained
- binary cross entropy cost function with softmax?
- Combinatorial Information Theory: I. Philosophical Basis of Cross-Entropy and Entropy
- word2vec gradients
- Softmax Regression